Probit
Ein Probit ist in der Statistik die zu einer Wahrscheinlichkeit
 gebildete Größe
gebildete Größe  ,
wobei
,
wobei  die Umkehrfunktion der Verteilungsfunktion
die Umkehrfunktion der Verteilungsfunktion
 der Standardnormalverteilung bezeichnet. Unter der
Probit-Transformation versteht man die Transformation von Wahrscheinlichkeiten in Probits. Diese Transformation wird im Probit-Modell, einem
speziellen verallgemeinerten linearen Modell, zur Spezifikation der Kopplungsfunktion verwendet.
der Standardnormalverteilung bezeichnet. Unter der
Probit-Transformation versteht man die Transformation von Wahrscheinlichkeiten in Probits. Diese Transformation wird im Probit-Modell, einem
speziellen verallgemeinerten linearen Modell, zur Spezifikation der Kopplungsfunktion verwendet.
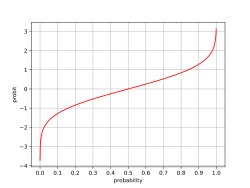
In der Biometrie werden in der sogenannten Probitanalyse zur Untersuchung von Dosis-Wirkung-Beziehungen die Begriffe Probit und Probit-Transformation in einer verwandten, aber abweichenden Bedeutung verwendet.
Definition
Für eine Wahrscheinlichkeit  heißt
heißt

Probit von
die Verteilungsfunktion der Standardnormalverteilung bezeichnet.
Die Funktion  heißt auch Probit-Funktion. Wenn Wahrscheinlichkeiten
in
heißt auch Probit-Funktion. Wenn Wahrscheinlichkeiten
in  transformiert werden, spricht man auch von einer Probit-Transformation.
transformiert werden, spricht man auch von einer Probit-Transformation.
Eigenschaften
- Es gilt

- Die Probit-Funktion besitzt die Symmetrieeigenschaft

- Die Probit-Funktion ist streng monoton und hat die Grenzwerte

- Die Probit-Funktion ist differenzierbar und hat die Ableitungsfunktion
- wobei
 die Dichtefunktion der Standardnormalverteilung bezeichnet.
die Dichtefunktion der Standardnormalverteilung bezeichnet.

- Die Probit-Funktion ist invertierbar. Ihre Umkehrfunktion ist die Verteilungsfunktion der Standardnormalverteilung.
- Formal ist
 das
das  -Quantil der Standardnormalverteilung und die Probit-Funktion ist die
Quantilfunktion einer standardnormalverteilten Zufallsvariablen.
-Quantil der Standardnormalverteilung und die Probit-Funktion ist die
Quantilfunktion einer standardnormalverteilten Zufallsvariablen.
Anwendungen
- Die Bezeichnung Probit hat sich in bestimmten Anwendungsgebieten der Statistik durchgesetzt, auch als sprachliche Parallele zu Logit.
- Mit binären Regressionsmodellen wird die Wahrscheinlichkeitsverteilung einer erklärten binären Variable mit den möglichen Werten 0 und 1 durch eine affin lineare Funktion erklärender Variablen bestimmt. Im Probit-Modell[1][2] wird die Probit-Funktion zur Verbindung der Verteilung der erklärten Variablen mit den erklärenden Variablen verwendet,
- Dabei ist
 der
der
 -te
beobachtete Werte der
-te
beobachtete Werte der  -ten
erklärenden Variablen und
-ten
erklärenden Variablen und  ist die Anzahl der Beobachtungen. Eine häufig verwendete Alternative zum Probit-Modell ist das Logit-Modell, bei dem die
Logit-Funktion
ist die Anzahl der Beobachtungen. Eine häufig verwendete Alternative zum Probit-Modell ist das Logit-Modell, bei dem die
Logit-Funktion
 an die Stelle der Probit-Funktion tritt.
an die Stelle der Probit-Funktion tritt.

- Mit ordinalen Regressionsmodellen wird die Wahrscheinlichkeitsverteilung
einer erklärten ordinalen Variable, die eine endliche Anzahl von Kategorien hat, durch eine affin lineare Funktion erklärender Variablen bestimmt. Im ordinalen Probit-Modell werden in der Variante des kumulativen Modells
für die erklärte kategoriale Variable mit
 Kategorien die Wahrscheinlichkeiten
Kategorien die Wahrscheinlichkeiten
 für
für  als
als
- modelliert.[3] Dabei gilt
 .
Wie im binären Probit-Modell kann anstelle der Probit-Funktion die Logit-Funktion verwendet werden.
.
Wie im binären Probit-Modell kann anstelle der Probit-Funktion die Logit-Funktion verwendet werden.

- Im Bereich der Ökonometrie wird das Probit-Modell gerne verwendet, da es als ein Schwellenwert-Modell mit einem latenten normalverteilten Fehlerterm interpretiert werden kann.[4] Dagegen wird in biometrischen Anwendungen überwiegend die Logit-Variante des Modells verwendet, da die Logits Logarithmen der Odds (bzw. der kumulativen Odds im Fall des ordinalen Modells) sind, da Odds und Chancenverhältnisse im Bereich der Biometrie eine wichtige Rolle spielen.[3]
Probitanalyse in der Biometrie
In der Biometrie heißt ein Teilgebiet der Untersuchung von Dosis-Wirkung-Beziehungen Probitanalyse[5][6].
Dort findet sich folgende abweichende Terminologie für den Begriff Probit-Transformation. Für eine Zufallsvariable
 ,
deren dekadischer Logarithmus
,
deren dekadischer Logarithmus
 einer Normalverteilung mit den Parametern
einer Normalverteilung mit den Parametern
 und
und  genügt, ist die Zufallsvariable
genügt, ist die Zufallsvariable
 standardnormalverteilt und die Zufallsvariable
standardnormalverteilt und die Zufallsvariable
 nimmt mit sehr großer Wahrscheinlichkeit positive Werte an. Die Transformation der Messwerte
nimmt mit sehr großer Wahrscheinlichkeit positive Werte an. Die Transformation der Messwerte

heißt in diesem Zusammenhang Probit-Transformation. In diesem Zusammenhang wird der zu einer Wahrscheinlichkeit
gehörende Probit als der Wert
 definiert.[7]
definiert.[7]
Einzelnachweise
- ↑ Gerhard Tutz: Die Analyse kategorialer Daten – Anwendungsorientierte Einführung in Logit-Modellierung und kategoriale Regression. Oldenbourg, München / Wien 2000, ISBN 3-486-25405-7, 4.2.1 Probit-Modell, S. 122.
- ↑ Gerhard Tutz: Regression for Categorical Data. Cambridge University Press, Cambridge 2012, ISBN 978-1-107-00965-3, Probit Model, S. 123–124.
- ↑ Hochspringen nach: a b Gerhard Tutz: Regression for Categorical Data. Cambridge University Press, Cambridge 2012, ISBN 978-1-107-00965-3, Probit Model, S. 248.
- ↑ Gerhard Tutz: Modelle für kategoriale Daten mit ordinalem Skalenniveau – Parametrische und nonparametrische Ansätze. Vandenhoeck & Ruprecht, Göttingen 1990, ISBN 3-525-11268-8, S. 76–77.
- ↑ P. H. Müller (Hrsg.): Lexikon der Stochastik – Wahrscheinlichkeitsrechnung und mathematische Statistik. 5. Auflage. Akademie-Verlag, Berlin 1991, ISBN 978-3-05-500608-1, Probitanalyse, S. 307–309.
- ↑ D. J. Finney: Probit Analysis. 3. Auflage. Cambridge University Press, Cambridge 1971.
- ↑ P. H. Müller (Hrsg.): Lexikon der Stochastik – Wahrscheinlichkeitsrechnung und mathematische Statistik. 5. Auflage. Akademie-Verlag, Berlin 1991, ISBN 978-3-05-500608-1, Probitanalyse, S. 308.


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 02.07. 2025